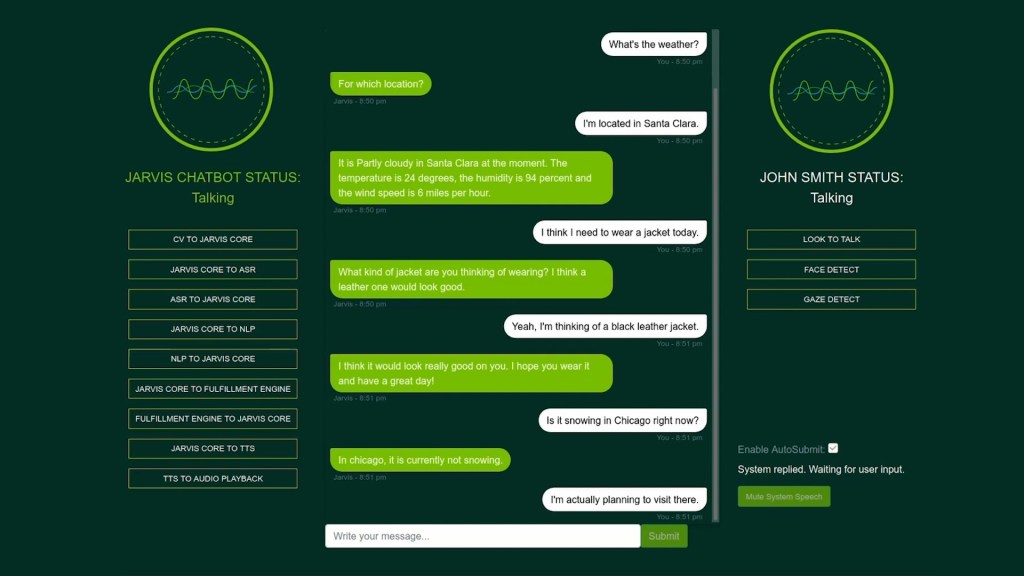
Speech to text is so old school. How about speech to real-time multi-language translation? Or text to speech? Imagine the massive possibilities if such capabilities are available.
The good news is that the newly-announced NVIDIA Jarvis framework can empower developers with pre-trained deep learning models and software tools to create interactive conversational AI services that can be easily adapted.
Traned on on more than one billion pages of text, 60,000 hours of speech data, and in different languages, accents, environments and lingos, NVIDIA Jarvis models offer highly accurate automatic speech recognition, as well as superhuman language understanding, real-time translations for multiple languages, and new text-to-speech capabilities to create expressive conversational AI agents.
Utilising GPU acceleration, the end-to-end speech pipeline can be run in under 100 milliseconds — listening, understanding and generating a response faster than the blink of a human eye — and can be deployed in the cloud, in the data centre or at the edge, instantly scaling to millions of users.
“Conversational AI is in many ways the ultimate AI. Deep learning breakthroughs in speech recognition, language understanding and speech synthesis have enabled engaging cloud services. NVIDIA Jarvis brings this state-of-the-art conversational AI out of the cloud for customers to host AI services anywhere,” said Jensen Huang, Founder and CEO of NVIDIA.
NVIDIA Jarvis will enable a new wave of language-based applications such as digital nurses to help monitor patients around the clock, online assistants to understand what consumers are looking for and recommend the best products, and real-time translations to improve cross-border workplace collaboration.
Its newly announced features will be released in the second quarter as part of the ongoing open beta programme.
